Research Vision
I aim to build a unified perception system that robustly predicts the evolution of the dynamic environment in the future and makes inference into occluded regions in order to intelligently inform autonomous decision making.
Spatiotemporal Environment Prediction
|
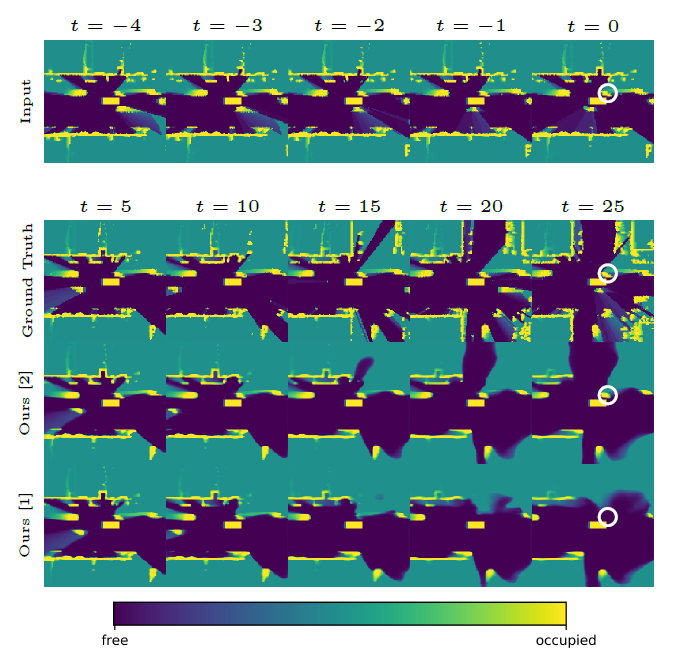
One of the key challenges in autonomous driving is safely planning a trajectory in a cluttered, urban environment with dynamic obstacles. Information regarding the future state of the world, specifically, regarding the behavior of other dynamic agents, would allow a planning algorithm to plan a trajectory reactively to a dynamic, rapidly changing environment. An occupancy grid map representation of the surroundings is typically used for autonomous vehicles. We frame environment prediction within an occupancy grid as a video-frame prediction problem. We propose accounting for the temporal data structure of sequential occupancy grid input data using an convolutional LSTM. We investigate how network architecture (e.g., attention mechanisms) and input representation affect prediction quality and dynamic object retention on real-world data.
[1] M. Itkina, K. Driggs-Campbell, and M. J. Kochenderfer, “Dynamic environment prediction in urban scenes using recurrent representation learning,” in International Conference on Intelligent Transportation Systems (ITSC), IEEE, 2019. [2] B. Lange, M. Itkina, and M. J. Kochenderfer, “Attention augmented ConvLSTM for environment prediction,” in International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021. [3] M. Toyungyernsub, M. Itkina, R. Senanayake, and M. J. Kochenderfer, “Double-prong occupancy ConvLSTM: Spatiotemporal prediction in urban environments,” in International Conference on Robotics and Automation (ICRA), IEEE, 2021. |
|
Occlusion Inference Using People as Sensors
|
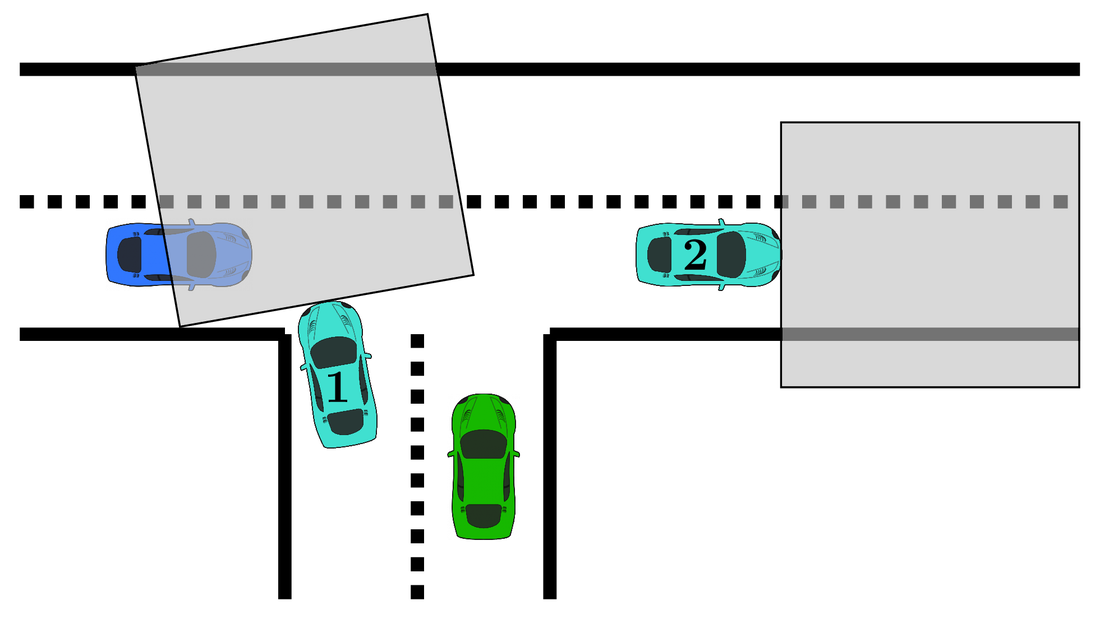
Autonomous vehicles must reason about spatial occlusions in urban environments to ensure safety without being overly cautious. Prior work explored occlusion inference from observed social behaviors of road agents, hence treating people as sensors. Inferring occupancy from agent behaviors is an inherently multimodal problem; a driver may behave similarly for different occupancy patterns ahead of them (e.g., a driver may move at constant speed in traffic or on an open road). Past work, however, does not account for this multimodality, thus neglecting to model this source of aleatoric uncertainty in the relationship between driver behaviors and their environment. We propose an occlusion inference method that characterizes observed behaviors of human agents as sensor measurements, and fuses them with those from a standard sensor suite. To capture the aleatoric uncertainty, we train a conditional variational autoencoder with a discrete latent space to learn a multimodal mapping from observed driver trajectories to an occupancy grid representation of the view ahead of the driver. Our method handles multi-agent scenarios, combining measurements from multiple observed drivers using evidential theory to solve the sensor fusion problem.
[4] M. Itkina, Y.-J. Mun, K. Driggs-Campbell, and M. J. Kochenderfer, “Multi-agent variational occlusion inference using people as sensors,” in International Conference on Robotics and Automation (ICRA), 2022. [5] Y.-J. Mun, M. Itkina, S. Liu, and K. Driggs-Campbell, "Occlusion-aware crowd navigation using people as sensors," Under Review, 2022. |
Evidential Sparsification of Multimodal Latent Spaces in
Deep Generative Models
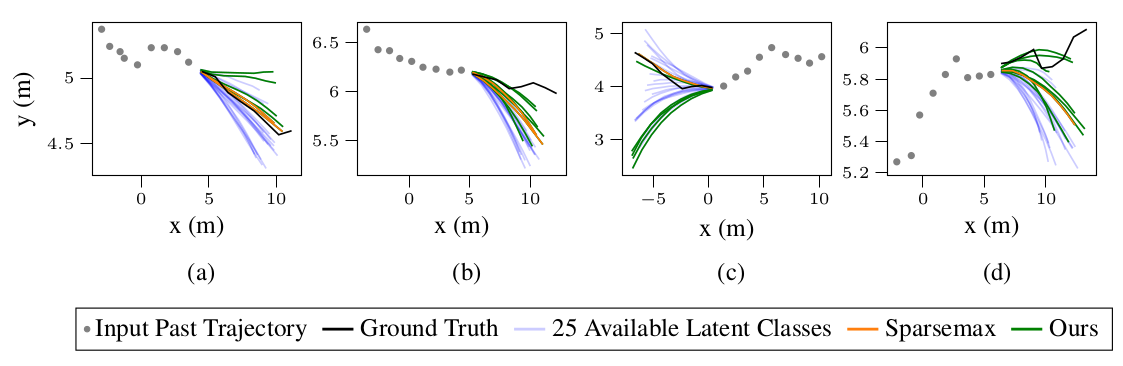
Discrete latent spaces in variational autoencoders have been shown to effectively capture the data distribution for many real-world problems such as natural language understanding, human intent prediction, and visual scene representation. However, discrete latent spaces need to be sufficiently large to capture the complexities of real-world data, rendering downstream tasks computationally challenging. For instance, performing motion planning in a high-dimensional latent representation of the environment could be intractable. We consider the problem of sparsifying the discrete latent space of a trained conditional variational autoencoder, while preserving its learned multimodality. As a post hoc latent space reduction technique, we use evidential theory to identify the latent classes that receive direct evidence from a particular input condition and filter out those that do not.
[6] M. Itkina, B. Ivanovic, R. Senanayake, M. J. Kochenderfer, and M. Pavone, “Evidential sparsification of multimodal latent spaces in conditional variational autoencoders,” in Advances in Neural Information Processing Systems (NeurIPS), 2020.
[7] P. Chen, M. Itkina, R. Senanayake, M. J. Kochenderfer, "Evidential softmax for sparse multimodal distributions in deep generative models," in Advances in Neural Information Processing Systems (NeurIPS), 2021.
[6] M. Itkina, B. Ivanovic, R. Senanayake, M. J. Kochenderfer, and M. Pavone, “Evidential sparsification of multimodal latent spaces in conditional variational autoencoders,” in Advances in Neural Information Processing Systems (NeurIPS), 2020.
[7] P. Chen, M. Itkina, R. Senanayake, M. J. Kochenderfer, "Evidential softmax for sparse multimodal distributions in deep generative models," in Advances in Neural Information Processing Systems (NeurIPS), 2021.
Robust Perception
|
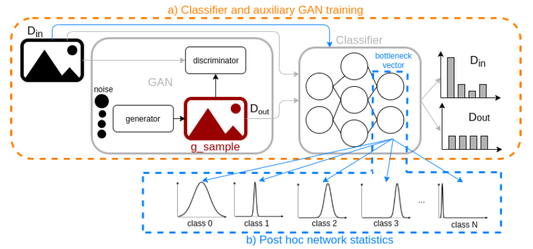
Neural networks have become quintessential tools for computer vision. However, they often fail on inputs outside of their training distribution, known as out-of-distribution (OOD) data. Detecting OOD samples and understanding the situations that lead to system failure is paramount for safety-critical applications. We present a simple but effective method for OOD detection which combines auxiliary training techniques with post hoc statistics. Our proposed method does not require OOD data during training, and it does not increase the computational cost during inference, which is important in robotics applications with real-time constraints. Our proposed method outperforms state-of-the-art methods on real world datasets.
We also consider how we can identify the most likely ways in which perception systems might fail, for example in adverse weather conditions. We develop a methodology based in reinforcement learning to find likely failures in object tracking and trajectory prediction due to sequences of disturbances. We apply disturbances using a physics-based data augmentation technique for simulating LiDAR point clouds in adverse weather conditions. Identified failures can inform future development of robust perception systems. [8] J. Nitsch, M. Itkina, R. Senanayake, J. Nieto, M. Schmidt, R. Siegwart, M. J. Kochenderfer, and C. Cadena, “Out of distribution detection for automotive perception,” in International Conference on Intelligent Transportation Systems (ITSC), IEEE, 2021. [9] H. Delecki, M. Itkina, B. Lange, R. Senanayake, and M. J. Kochenderfer, "How do we fail? Stress testing perception systems for autonomous vehicle," Under Review, 2022. |
|
